
AI GPU高速互联技术全景解析:从PCIe到超以太网
随着大模型参数规模呈指数级增长——百度文心一言拥有2600亿参数,GPT-4更是突破万亿级别——单卡GPU的显存容量已成为明显瓶颈。即使配备80GB显存...
随着大模型参数规模呈指数级增长——百度文心一言拥有2600亿参数,GPT-4更是突破万亿级别——单卡GPU的显存容量已成为明显瓶颈。即使配备80GB显存的A800 GPU,扣除训练中间变量后,实际仅能存储10-20亿参数。这意味着,训练一个千亿级参数的模型,往往需要上百块GPU协同工作。
在这样的背景下,分布式训练成为大模型开发的必然选择,而构建低延迟、高带宽的互联网络,则是释放分布式算力的关键所在。
互联的层次:从单卡到集群
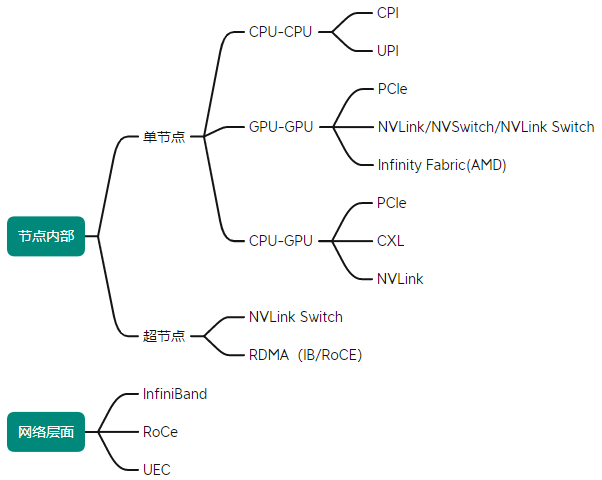
在分布式系统中,网络互联可分为三个层次:
-
单卡内部:用于神经网络计算的基础连接
-
多卡互联(GPU互联):通常采用PCIe或各种高带宽通信协议
-
多机互联(服务器互联):主要采用远程直接内存访问(RDMA)技术
单机多卡互联技术
PCIe协议:基础但存在瓶颈
PCIe(PCI-Express)是目前应用最广泛的总线协议,主要用于连接CPU与GPU、SSD、网卡等高速设备。自2003年发布以来,PCIe已发展至6.0版本,传输速率高达64GT/s,16通道带宽达到256GB/s。
然而,PCIe在GPU多卡通信中面临三个关键挑战:
-
带宽瓶颈:GPU互联通常需要数百GB/s的带宽,PCIe难以满足
-
延迟问题:链路接口的串并转换、PCIe交换机的数据处理都会引入额外延迟
-
内存访问开销:PCIe总线与内存地址分离,每次内存访问都会加剧延迟
PCIe交换机:扩展连接能力
PCIe采用点对点传输,链路两端各自只能连接一个设备。PCIe交换机的出现解决了这一问题——它使单个PCIe端口能够连接多个设备,并将多条PCIe总线相互连接,形成一个高速网络。
替代PCIe的高效协议
为了突破PCIe的限制,业界推出了多种替代协议:
| 协议 | 特点 | 发展现状 |
|---|---|---|
| CAPI/Open CAPI | IBM推出,增加缓存一致性和低延迟特性 | 因IBM服务器市场份额下降,应用有限 |
| GenZ | 开放性组织,将总线协议拓展为交换式网络 | 已被CXL吸收合并 |
| CXL | 英特尔2019年推出,具备内存接口 | 已合并GenZ和Open CAPI,成为主流标准之一 |
| CCIX | ARM参与的开放协议 | 未被主要合并所涵盖 |
| Infinity Fabric | AMD专利技术,连接不同功能模块 | 用于on-die和off-die及多路CPU间通信 |
NVLink:英伟达的高速GPU互联方案
英伟达提出的NVLink协议,在三个方面做出了重大改变:
-
网状拓扑结构:解决通道有限的问题,支持更灵活的GPU连接方式
-
统一内存:允许GPU共享公共内存池,减少数据复制需求
-
直接内存访问:无需CPU参与,GPU可直接访问彼此内存,显著降低延迟
为进一步解决GPU间通信不均衡的问题,英伟达推出了NVSwitch——一种类似交换机的专用集成电路芯片。2023年推出的DGX GH200超级计算机,正是通过NVLink和NVSwitch连接了256个GH200芯片,实现超过100TB的可访问内存。
其他厂商的高速互联技术
-
寒武纪:MLU-LINK
-
燧原科技:GCU-LARE
-
壁仞科技:B-LINK
多机互联:RDMA技术
在多设备分布式训练中,远程直接内存访问(RDMA)已成为首选技术。与传统TCP/IP网络需要通过内核发送消息、涉及数据移动和复制不同,RDMA允许无需内核干预、不占用CPU资源的情况下直接远程访问内存数据,显著提升性能并降低延迟。
三种RDMA实现方式
1. InfiniBand(IB)
-
专为RDMA设计的网络,从硬件层面保证可靠传输
-
具备更高带宽和更低时延
-
成本较高,需要配套的IB网卡和交换机
2. RoCE(融合以太网上的RDMA)
-
基于以太网实现RDMA
-
可使用标准以太网交换机,成本较低
-
需要支持RoCE的网卡
3. iWARP(互联网广域RDMA协议)
-
基于TCP的RDMA网络,利用TCP实现可靠传输
-
可使用标准以太网交换机
-
需要支持iWARP的网卡
-
在大型网络中,大量TCP连接会消耗较多内存资源
面向未来的UEC标准
超以太网联盟(Ultra Ethernet Consortium,UEC)由AMD、Arista、Broadcom、Cisco、HPE、Intel、Meta、Microsoft等行业领导者组成,旨在优化以太网标准,以更好地支持AI、机器学习和高性能计算不断增长的需求。
UET的核心特性
超以太网传输(Ultra Ethernet Transport,UET)是下一代面向AI超算和HPC的网络协议,其主要特点包括:
-
多路径+数据包喷洒技术:充分利用高带宽网络,无需负载平衡算法
-
保留IP协议:本质上仍是开放协议
-
播送管理机制:减少掉线
-
支持无序数据包发送:提升网络并发性能
-
百万级端口支持:满足AI超算和HPC集群所需的交换规模
UET针对有损网络下的队头堵塞和堵塞扩散问题提出了创新解决方案,目前规范仍在制定中。
总结与展望
从单机多卡的PCIe、NVLink,到多机互联的InfiniBand、RoCE,再到正在制定的UEC标准,AI GPU互联技术正朝着更高带宽、更低延迟、更强可扩展性的方向持续演进。
在大模型训练需求不断攀升的今天,互联技术已成为决定算力集群效率的核心要素。无论是英伟达的NVLink+NVSwitch方案,还是业界共同推动的UEC标准,都在为下一代AI基础设施铺平道路。理解这些技术的特性与适用场景,对于构建高效、可扩展的AI计算集群至关重要。



AI GPU高速互联技术全景解析:从PCIe到超以太网 方案咨询常见问题
这个方案适合哪些业务场景?
可围绕 AI 集群、HPC 高性能计算、数据中心高速互联、GPU 服务器互联、InfiniBand/RDMA 或 RoCE 网络升级进行评估,具体需结合节点规模、带宽、时延、扩容和预算确认。
方案里需要哪些 NVIDIA/Mellanox 产品?
常见会涉及 NVIDIA Quantum 或 Spectrum 交换机、ConnectX 网卡、BlueField DPU、OSFP/QSFP 光模块、DAC/AOC 线缆等,实际清单需结合拓扑、距离和端口规划。
如何做方案报价和产品清单?
建议提供服务器数量、GPU/业务类型、目标带宽、机柜距离、冗余要求、现有网络设备和期望交付周期,便于整理交换机、网卡、光模块、线缆和替代型号建议。
如何确认兼容性和落地风险?
需要核对服务器平台、交换机端口、网卡形态、线缆/光模块、驱动固件、网络协议和现场布线条件,避免单独采购某一类产品导致整体链路不匹配。
如果您正在规划 AI 网络、数据中心或高速互联方案
我们可以结合业务场景,为您提供可落地的产品清单、架构建议和部署支持。