



MQM9790-NS2F 选型、兼容与采购说明
围绕 NVIDIA Quantum InfiniBand交换机 组网选型,本页补充 MQM9790-NS2F 的应用场景、参数选型、兼容性确认、企业采购报价和替代型号沟通信息,帮助客户在搜索“MQM9790-NS2F 参数”“MQM9790-NS2F 报价”“MQM9790-NS2F 兼容性”“NVIDIA Quantum InfiniBand交换机 组网选型 选型”时更快判断是否适合当前项目。
应用场景与项目需求
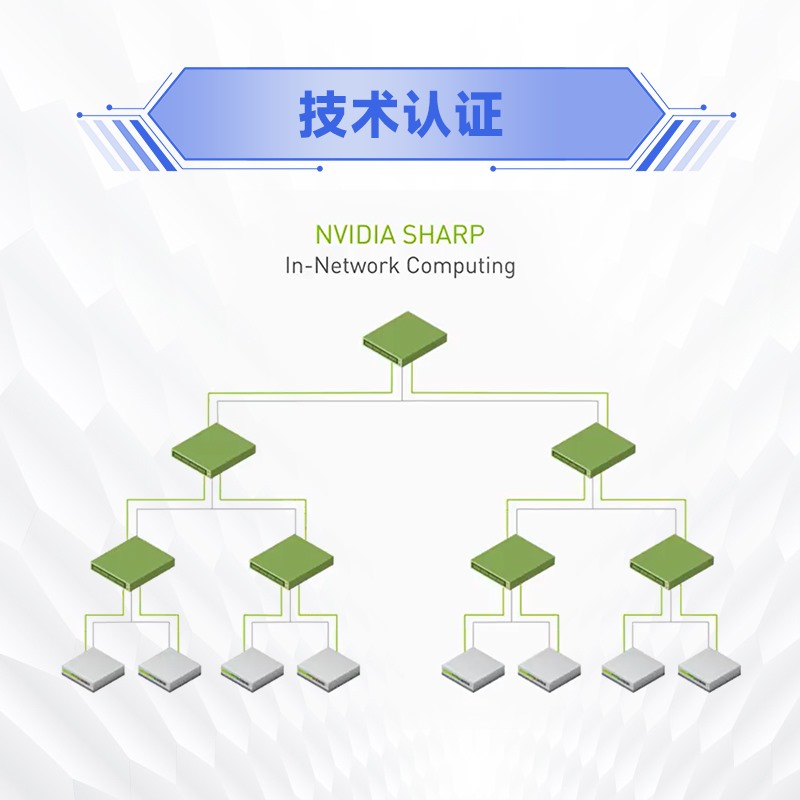
适用于 AI 训练集群、HPC 高性能计算、GPU 服务器互联和低时延 RDMA 网络,常见咨询包括端口数量、端口速率、叶脊架构、线缆/光模块配套和集群扩容。
参数选型与替代型号
选型时建议同步确认节点数量、GPU/服务器规模、端口速率、冗余架构、线缆距离、未来扩容空间和与网卡型号的匹配关系。
兼容性确认与报价沟通
兼容性确认应覆盖交换机端口、网卡型号、线缆/光模块、管理方式、网络拓扑和现有机房布线条件。 如需报价,建议同时提供数量、使用场景和期望交期。
NVIDIA InfiniBand交换机
Quantum交换机
AI集群交换机
HDR NDR交换机
RDMA组网方案
InfiniBand交换机报价